
Most of us are familiar with how a web application works. We know that when we enter an URL in our browser, it’ll contact a web server who’ll return some HTML. The browser will then make follow-up requests and then render the web page. (This is a simplification! But that’s the main idea.)
But what’s happening on the web server returning HTML? How is the web server getting the HTML that it returns to our browser? And, to be even more specific, how does this happen in PHP?
This isn’t something that most of us know how to answer. We know (or at least should know!) how to build a PHP website. But what happens between our PHP code and the browser is a bit of a mystery.
There’s a good chance that you’re thinking, “Well, my site loads. Why should I think twice about this?” And that’s true! But the truth is that knowing how a PHP application works can be useful.
It can affect how you design your PHP application. But it’s also important if you’re looking to improve its performance. For example, it’s hard to understand PHP application caching if you don’t understand how a PHP application works.
The life of a PHP request
If you come from a compiled language (like Java or C#), the biggest thing to understand is that PHP isn’t one. It’s an interpreted language. This means that PHP will need to interpret and compile the code of your application for each request made to it.
Now, you can use caching and other optimizations to speed this process up. But the nature of how requests to your PHP application work won’t change. They’ll always look like this:

As you can see in the diagram above, we always start with a browser making a request for a web page. This request is going to hit the web server. The web server will then analyze it and determine what to do with it.
If the web server determines that the request is for a PHP file (often index.php), it’ll pass that file to the PHP interpreter. The PHP interpreter will read the PHP file, parse it (and other included files) and then execute it. Once the PHP interpreter finishes executing the PHP file, it’ll return an output. The web server will take that output and send it back as a response to the browser.
A PHP application is just a script
This was the goal of explaining the life cycle of a PHP request was to get to this statement. This is the truth behind any PHP application whether it’s a Laravel or Symfony application. (Or even a CMS like Drupal or WordPress.) They’re all nothing more than scripts much like a shell script.
In this scenario, the web server is nothing more than an intermediary. Each time that someone makes a request for a PHP page, it’s just asking the web server to run a specific PHP script. If the PHP script returns any output, the web server sends it back.
This is different to what you’ll see in with other web programming languages. These web programming languages create what we’ll call more traditional web applications. These traditional web applications often work using an application server. Some well-known application servers are Tomcat for Java, IIS for .NET, Gunicorn for Python, Unicorn for Ruby.
Working with an application server is different in some fundamental ways. The most important one is that a traditional web application resides within the application server. It’s not a script that your web server can call. In fact, these application servers also act as web servers. The diagram below should help you visualize this.
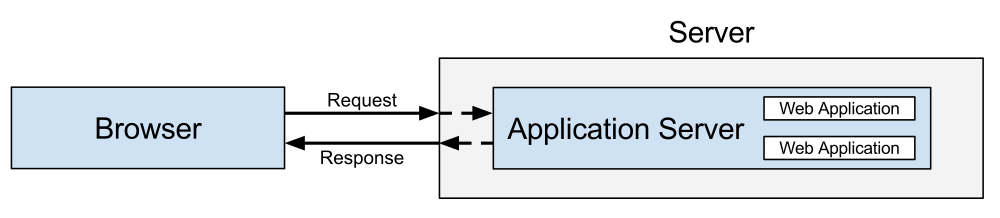
As you can see, the web application is inside of the application server. (There can even be more than one web application per application server!) This application server is also your web server. Any request that you make to it is the same as a request to the web application. It’s not an intermediary like it is with PHP.
Different dynamics
This fundamental difference between a PHP application and more traditional web application is important. It changes a lot of the dynamics around them. For example, this is why you can edit any PHP file on a server and see the changes right away. (Well, that’s unless you have some caching solution in place!)
But you can’t say the same about traditional web applications. These applications often only let you edit template files on the fly. Any other changes will require that you restart the application server at a minimum. (Things get more complicated if you use a compiled language.)
That said, this isn’t the only difference between a PHP application and a traditional one. There are other differences that are important to know. So let’s look at some of them.
Memory management
Let’s start with memory management. How do we manage memory when we’re working with a PHP application? The answer is that most of us don’t manage memory when we’re working on a PHP application.
We only do something if PHP gives us an out of memory error. And often we’ll just increase the PHP’s memory limit when we encounter that error. We’ll then move on and continue working on whatever we were working on before we saw the error.
If you’re more performance focused, you’ll try to reduce the memory usage of your code. For example, let’s say that you’re running out of memory storing a big XML file in memory using SimpleXML. You can switch to XMLReader to traverse the XML file instead.
Memory leaks
Have you ever encountered a memory leak with PHP? Memory leaks are the result of improper memory management like our out of memory errors. They happen you persist data in memory and that memory never gets cleared once you’re done with the data.
That said, memory leaks are quite rare with PHP applications. That’s because PHP is a script that runs and then terminates. Once terminated, PHP will clear all the memory used by the script. Resetting memory that way prevents most PHP applications from having memory leaks.
But this isn’t the case with a more traditional web application. Since the application is part of the web server, it only terminates when you restart the web server itself. This doesn’t (or shouldn’t!) happen very often. This means that memory leaks are a common reality with those types of applications.
Memory leaks have real consequences with a more traditional web application. If you don’t restart your application server, your server will run out of memory at some point. When that happens, the application server will crash taking your web application with it.
Data persistence
So we’re pretty clear on how what memory leaks are and why PHP doesn’t suffer from that problem much. But this isn’t the only unique aspect of memory management in PHP either. PHP also doesn’t have any built-in way to persist data in memory.
In fact, part of the reason why there are few memory leaks in PHP is because of this aspect of memory management in PHP. Let’s imagine that we have two identical requests for our PHP application. The first one runs through our PHP script and stores data in memory in the process. None of that data will be available to the second request.
This ties to what we explained about PHP scripts earlier. Once the PHP finishes executing a script, the operating system clears the memory that it used. This means that PHP can’t share data between requests by using memory like a traditional web application would.
Instead, PHP depends on other systems to share data between requests. You can use sessions which themselves use a storage method. A storage method could be a file, a data store or even a database.
A PHP application tends to make use of one or more of these storage methods. Which ones you use depends on what your application supports and your needs. But, if you have to pick one, using a data store like Redis or Memcached tends to be the most popular option.
Concurrency
Concurrency is another concept that’s important to understand with PHP applications. What is concurrency? It’s the idea that you can break down software into smaller parts. You can then execute these smaller parts at the same time or in a different order without anything breaking.
Now, explained like this, concurrency doesn’t really make sense with PHP applications. PHP doesn’t break down our application into smaller parts and run them at the same time. That said, concurrency still applies because of how PHP handles multiple requests to an application.
As we’ve seen so far, each request made to a PHP application is independent of the other. The web server will pass the request to the PHP interpreter who’ll run the script of our PHP application. This means that it’s very common for the PHP interpreter to be processing more than one script at the same time.

The timeline above attempts to highlight this using a timeline. We have three concurrent processes of a PHP script. They start and finish at different times, but some of their execution overlaps.
This is why you should keep concurrency in mind when working with a PHP application. And concurrency like memory management has more than one implication with PHP. That said, they’re not things that you have to think about all the time. (But it’s still good to know about them!)
Multitasking
Let’s start with multitasking. Multitasking is the idea that you can perform a set of computer tasks faster if you do them at the same time. PHP applications rely on this concept a lot to do computing intensive tasks.
That’s because it’s quite easy to implement multitasking in PHP. As we’ve seen already, it’s possible for the PHP interpreter to process more than one script at a time. So multitasking comes down to creating requests for these extra tasks that we need to do.

How does this work? Well, as you can see in the above diagram, you have an initial request to your PHP application. This initial request will cause the PHP application to generate other subrequests to itself. These other subrequests are our new application tasks. They run at the same time as our initial request.
It’s worth pointing out that these requests are often sent asynchronously. They don’t have a large impact on the execution time of a PHP script. This means that they don’t slow down the execution of the PHP application during the initial request.
A good example of multitasking in PHP applications is how popular PHP CMSs handle cron jobs. In a CMS, a cron job is a task that you scheduled (like publishing a future post) in the future that you need your CMS to handle. A CMS handles these cron jobs by creating a request for a specific URL whenever you make a request to the CMS.
Resource starvation
But concurrency isn’t without issues either. The most common one is resource starvation which means exactly what the name suggests. It refers to your concurrent PHP processes not having the resources they need to run well (or at all).
It’s worth pointing out that memory leaks which we saw earlier are a form of resource starvation. The growing memory leak starves the server’s memory until the application stops working. But, since PHP applications don’t suffer from memory leaks, it’s not the cause of the problem here.
Let’s imagine that your server has 300megs of free memory. And your PHP application takes on average 50megs of memory during its execution. This means that, in theory, your server can only handle six concurrent executions.
So what happens if your server needs to process more than six scripts at a time? Well, at this point, it depends on how your host configured your server. It could just slow down or it could outright die. (That’s the idea behind most denial-of-service attacks.)
This is why resource starvation isn’t so much of an issue with your PHP application. Yes, you could its reduce memory usage. And, as a result, you’d be able to have more concurrent executions of your PHP application.
But it would be better to configure your server so that it doesn’t ever try to do too many concurrent executions. That’s why it’s an important configuration setting for a PHP application server. Resource starvation is more of a server configuration issue than an application issue.
Race conditions
Another issue to be aware of with concurrency is race conditions. A race condition is a bit of a complicated problem that’s easier to explain with an example. A common example of a race condition is tracking page views. That said, most types of tracking are susceptible to race conditions.
![]()
Above is a timeline of our PHP code that’s tracking the page views. The page view tracking code is in pink. In it, we fetch the current number of page views, increment the number by one and then save the value again. This is all pretty straightforward so far.
Now, let’s add concurrency to the mix! What happens if there are multiple executions of our page view tracking PHP code at the same time? Well, let’s update our timeline and find out.

Everything looks ok in this timeline. We have multiple executions of our PHP code, but none of the pink bars overlap. Each execution is able to fetch the current number of page views, increment it by one and then save it again.
Race condition in practice
But what happens if multiple executions of our PHP code overlap? After all, it’s not realistic to expect our executions to be nice and spread out like that all the time. Well, this is where things start to break down.

Here’s a timeline where our three executions are closer in time to one another. As you can see, the execution of our page view tracking PHP code overlaps now. This code overlap is our race condition.
Because of it, the page view increment from the second process is incorrect. That’s because it fetches the page view count before the first process saved it back. So it counts the same number of page views as the first process.
But that’s not the end of it either! Because of the race condition, the third process also overwrites the number of page views recorded by the second process. If we had more concurrent processes, this would compound the problems caused by the race condition.
The result is an inaccurate tracking of the number of page views. Our page view tracking code ended up counting only two page views when it should’ve counted three. That’s a serious problem if you bothered to design such a system.
Fixing a race condition
So how do we fix the race condition in our page view tracking PHP code? The obvious solution is to not do it and use an external service like Google Analytics. But that’s not an especially useful solution if you want to learn to fix race conditions!
Well, the problem with race conditions is that there are countless ways to fix them. We can’t cover them all in this article. But let’s not let this prevent us from talking about it a bit!
The key to fixing a race condition is the concept of mutual exclusion. Mutual exclusion is itself a property of larger topic called concurrency control. And the point of concurrency control is to ensure that concurrent operations (like our tracking of page views) generate the correct results.
Now, let’s go back to mutual exclusion. Mutual exclusion is the idea that only one execution can enter a critical piece of code at a time. This prevents race conditions because you can’t have more than one execution of this piece of code at a time.
Mutual exclusion using a lock
And how can we implement mutual exclusion with PHP? One of the common ways to implement it is with a lock. You use a lock to limit the access to a resource. In this scenario, this would be the number of page views that we only want one process to access at a time.

This timeline shows what happens to our page view tracking code when we use a lock. The yellow bar in our timeline represents the time spent waiting for the other execution to release the lock. Our page view tracking code can only begin when that happens.
But even then, there’s more than one way of implementing a lock! For example, you could use a semaphore. This is a special variable or data type that you can use to determine if a resource is in use or not. There are semaphores in PHP so it’s one option that you have available.
Mutual exclusion using message passing
Another option besides using a lock is to use message passing. Message passing revolves around isolating a critical piece of code inside your web application. Once isolated, your code should never make a call to this piece of code ever again. Instead, it should send a message to the web application to run it for you.
So, in the case of our page view tracking code, we would isolate that code inside our application. We would then replace that code with code that sends a message to our application. This message would tell our application to run this code for us.
But how is that different from making a call to our page view tracking code? The critical element to message passing is that you send the message outside the current process. Your current process won’t run the critical piece of code that causes the race condition.
Instead, it’s another process that runs it. And that process can enforce mutual exclusion for that critical piece of code. This ends up preventing the race condition.
A lot of PHP applications use a message queue to implement their messaging system. The PHP application will send a message to the message queue. The message queue will then process each message one at a time in the order that it received them.
There are a lot of choices from message queue systems. Some frameworks (such as Laravel) also have their own message queue system. Either way, it’s a great way to implement mutual exclusion inside your PHP application.
PHP applications are unique
As you can see, PHP applications are in a category of their own. They don’t quite behave in ways that a lot of web developers are familiar with. This is especially true if they come from other programming languages. (But even PHP developers don’t always know how they work!)
That said, there are also some common elements with other programming languages. But it’s knowing what’s the same and what’s different that’s important in the end. It’ll help you do a better job architecting your solutions using PHP.