
I spoke at LoopConf 2018 on software complexity and how to manage it. This is the companion article that I wrote for it. If you’re just looking for the slides, click here. You can also find a recording of the talk here.
As developers, we spend a lot of time writing code. But we spend even more time maintaining that code. How often do we go back find that that code has become this tangled mess that we almost can’t understand? It’s probably more often than we want to admit!
We wonder, “How did this happen? How did this code get so messy?” Well, the most likely culprit is software complexity. Our code became so complex that it became hard to know what it did.
Now, software complexity isn’t a topic that developers are often familiar with when they start coding. We have other things to worry about. We’re trying to learn a new programming language or a new framework.
We don’t stop and think that software complexity could be making that job harder for us. But it is doing precisely that. We’re creating code that works, but that’s also hard to maintain and understand. That’s why we often come back and ask ourselves, “What was I thinking!? This makes no sense.”
That’s why learning about software complexity is important. It’ll help you increase the quality of your code so that these situations don’t happen as often. And this also has the added benefit of making your code less prone to bugs. (That’s a good thing even if debugging is a great learning tool!)
What is software complexity?
Let’s start by going of software complexity as a concept. Software complexity is a way to describe a specific set of characteristics of your code. These characteristics all focus on how your code interacts with other pieces of code.
The measurement of these characteristics is what determines the complexity of your code. It’s a lot like a software quality grade for your code. The problem is that there are several ways to measure these characteristics.
We’re not going to look at all these different measurements. (It wouldn’t be super useful to do so anyway.) Instead, we’re going to focus on two specific ones: cyclomatic complexity and NPath. These two measurements are more than enough for you to evaluate the complexity of your code.
Cyclomatic complexity
If we had to pick one metric to use for measuring complexity, it would be cyclomatic complexity. It’s without question the better-known complexity measurement method. In fact, it’s common for developers often use the terms “software complexity” and “cyclomatic complexity” interchangeably.
Cyclomatic complexity measures the number of “linearly independent paths” through a piece of code. A linearly independent path is a fancy way of saying a “unique path where we count loops only once”. But this is still a bit confusing, so let’s look at a small example using this code:
function insert_default_value($mixed)
{
if (empty($mixed)) {
$mixed = 'value';
}
return $mixed;
}
This is a pretty straightforward function. The insert_default_value has one parameter called mixed. We check if it’s empty and if it is, we set the string value as its value.
How to calculate cyclomatic complexity
You calculate cyclomatic complexity using a control flow graph. This is a graph that represents all the possible paths through your code. If we converted our code into a control flow graph, it would look like this:
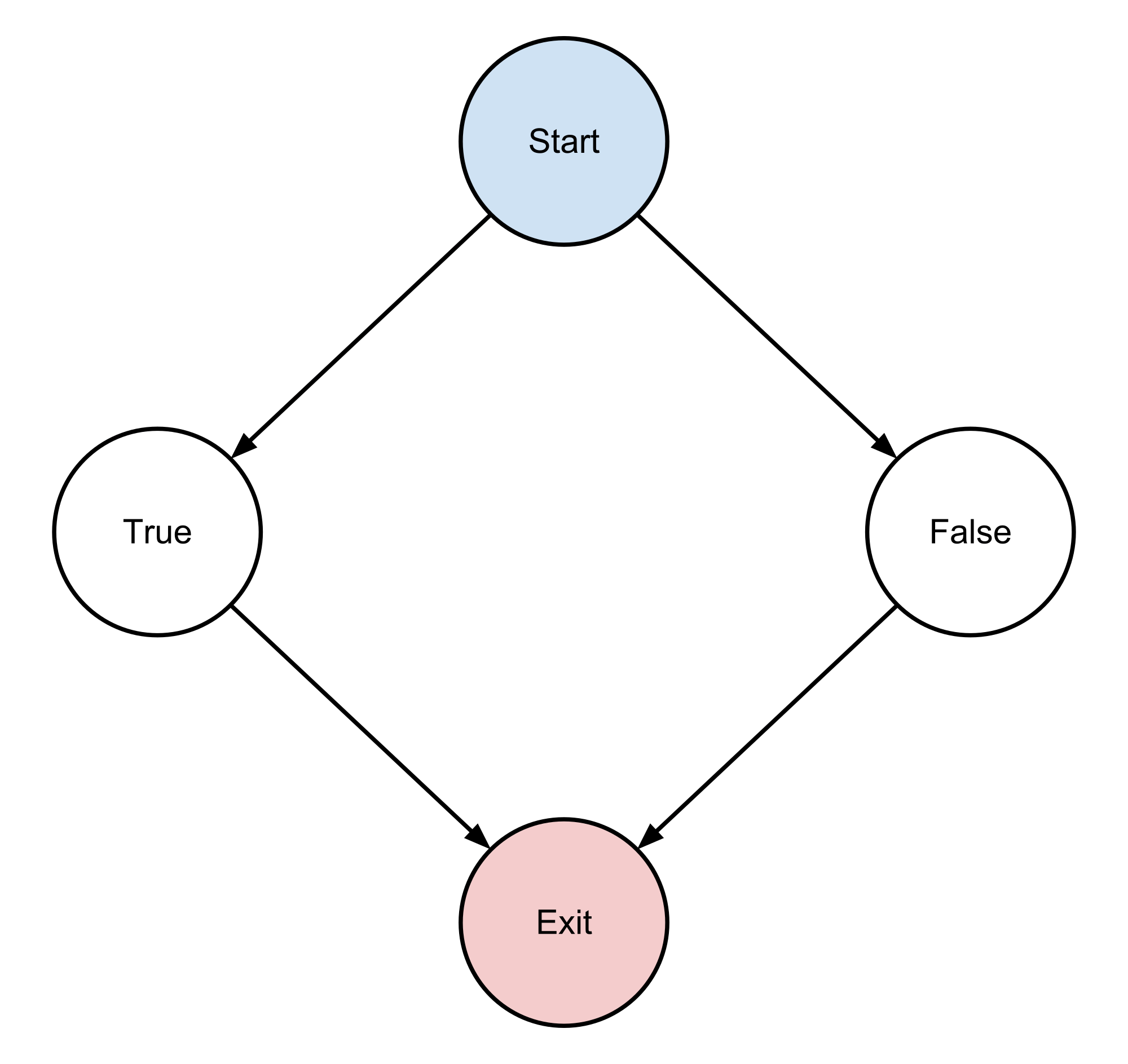
Our graph has four nodes. The top and bottom ones are for the beginning and end of the insert_default_value. The two other nodes are for the states when empty returns true and when it returns false.
Our graph also has four edges. Those are the arrows that connect our four nodes. To calculate the cyclomatic complexity of our code, we use these two numbers in this formula: M = E − N + 2.
M is the calculated complexity of our code. (Not sure why it’s an M and not a C.) E is the number of edges and N is the number of nodes. The 2 comes from a simplification of the regular cyclomatic complexity equation. (It’s because we’re always evaluating a single function or method.)
So what happens if we plug our previous numbers into our formula? Well, we get a cyclomatic complexity of M = 4 − 4 + 2 = 2 for the insert_default_value function. This means that there are two “linearly independent paths” through our function.
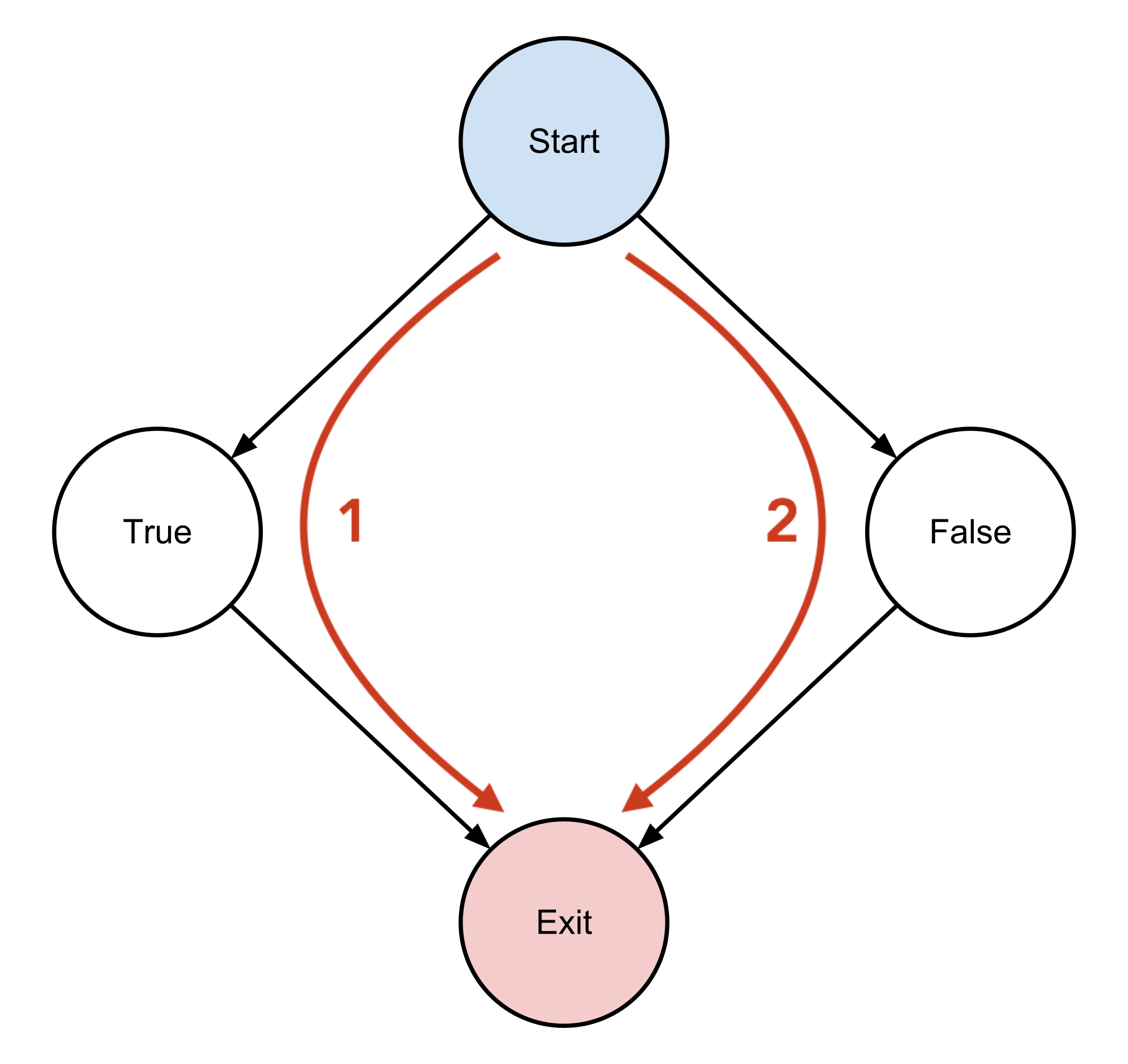
This is pretty easy to see in our updated graph above. One path was for if our if condition was true and the other was for if it wasn’t. We represented these two paths with red arrows on each side of the control flow graph.
Alternative way to calculate it
Now looking at what we just did, it’s pretty clear that cyclomatic complexity isn’t that user-friendly. Most of us don’t have mathematics degrees. And we sure don’t want to draw graphs and fill values in formulas while we’re coding!
So what can we do instead? Well, there’s a way to calculate the cyclomatic complexity without having to draw a graph. You want to count every if, while, for and case statements in your code as well as the entry to your function or method.
function insert_default_value($mixed) // 1
{
if (empty($mixed)) { // 2
$mixed = 'value';
}
return $mixed;
}
It’s worth noting that with if statements you have to count each condition in it. So, if you had two conditions inside your if statement, you’d have to count both. Here’s an example of that:
function insert_default_value($mixed) // 1
{
if (!is_string($mixed) || empty($mixed)) { // 2,3
$mixed = 'value';
}
return $mixed;
}
As you can see, we added a is_string before the empty check in our if statement. This means that we should count our if statement twice. This brings the cyclomatic complexity of our function to 3.
What’s a good cyclomatic complexity value?
Alright, so you now have a better idea of what cyclomatic complexity is and how to calculate it. But this doesn’t answer everything. You’re still asking yourself, “How do I know if my function is too complex? What cyclomatic complexity value will tell me that?”
As a general rule, if you have a cyclomatic complexity value between 1 and 4, your code isn’t that complex. We don’t tend to think of code within that range as complex either. Most small functions of a dozen lines of code or less fit within that range.
A cyclomatic complexity value between 5 and 7 is when things start unravelling. When your code is in that range, its complexity becomes noticeable. You can already start looking at ways to reduce complexity. (We’ll see what you can do to reduce complexity later in the article.)
But what if your code’s cyclomatic complexity is even higher? Well at that point, you’re now well into the “complex code” territory. A value between 8 and 10 is often the upper limit before code analysis tools will start warning you. So, if your code has a cyclomatic complexity value over 10, you shouldn’t hesitate to try and fix it right away.
Issues with cyclomatic complexity
We already discussed the role of mathematics in cyclomatic complexity. If you love math, that’s great. But it’s not that intuitive if you’re not familiar with mathematical graphs.
That said, there are two conceptual problems with cyclomatic complexity. Unlike the issue with mathematics, these two issues are quite important. That’s because they affect the usefulness of cyclomatic complexity as a metric.
Not every statement is equal
The first one is that cyclomatic complexity considers all if, while, for and case statements as identical. But, in practice, this isn’t the case. For example, let’s look at a for loop compared to an if condition.
With a for loop, the path through it is always the same. It doesn’t matter if you loop through it once or 10,000 times. It’s always the same code that gets processed over and over.
This isn’t the case with an if condition. It isn’t linear like a for loop. (It’s more like a fork in a road.) The path through your code will change depending on whether that if condition is true or false.
These alternative paths through your code have a larger effect on its complexity than a for loop. All the more so if your if conditions contain a lot of code. In those situations, the difference between your if condition being true or false can be significant.
Nesting
The other problem with cyclomatic complexity is that it doesn’t account for nesting. For example, let’s imagine that you had code with three nested for loops. Well, cyclomatic complexity considers them as complex as if they were one after the other.
But we’ve all seen nested for loops before. They don’t feel as complex as a linear succession of for loops. In fact, they more often than not feel more complex.
This is due in part to the cognitive complexity of nested code. Nested code is harder to understand. It’s something that a complexity measurement should take into consideration.
After all, we’re the ones who are going to debug this code. We should be able to understand what it does. If we can’t, it doesn’t matter whether it’s complex or not.
Complex vs complicated
The idea that code feels complex or is harder to understand is worth discussing. That’s because there’s a term that we use to describe that type code: complicated. It’s also common to think that complex and complicated mean the same thing.
But that’s not quite the case. We use these two terms to describe two different things in our code. The confusion comes from the fact that our code is often both complex and complicated.
So far, we’ve only discussed the meaning of complex. When we say that code is complex, we’re talking about its level of complexity. It’s code that has a cyclomatic complexity value. (Or a high value in another measurement method.) It’s also something that’s measurable.
Defining complicated code
But, when we say that code is complicated, it doesn’t have anything to do with complexity. It has to do with the psychological complexity that we talked about with nesting. It’s the answer to the question, “Is your code hard to understand?”
If the answer is “yes” then it’s complicated. Otherwise, it’s not complicated. But whatever the answer may be, it’s still subjective.
Code that’s complicated for you might not be for someone else. And the opposite is true as well. Code that isn’t complicated for you might be complicated for someone else. (Or even your future self!)
This also means that code that was once complicated can become straightforward. (And vice versa!) If you take the time that you need, you can figure out how complicated code works. At that point, it isn’t complicated anymore.
But that’ll never be the case with complex code. That’s because, when we say that code is complex, we base that on a measurement. And that measurement will never change as long as that code stays the same.
What makes code complex and complicated?
Now, let’s talk about why the two terms get confused. If you think about what makes code complex, it’s the number of statements in it. (Well, that’s the simple way to look at it.) The more statements there are, the higher the cyclomatic complexity will be.
But code that has a lot of statements in it isn’t just complex. There’s also more going on. It’s harder to keep track of everything that’s going on. (Even more so if a lot of the statements are nested.)
That’s what makes complex code harder to understand. It’s also why it’s common to think that the two terms mean the same thing. But, as we just saw, that’s not the case.
In fact, your code can be complicated without being complex. For example, using poor variable names is a way to make your code complicated without making it complex. It’s also possible for complex code to not be complicated as well.
NPATH
So this gives us a better understanding of what complicated code means. Now, we can move on and discuss another way to measure the complexity of a piece of code. We call this measurement method NPATH.
Unlike cyclomatic complexity, NPATH isn’t as well known by developers. There’s no Wikipedia page for it. (gasp) You have to read the paper on it if you want to learn about it. (Or keep reading this article!)
The paper explains the shortcomings of cyclomatic complexity. Some of which we saw earlier. It then proposes NPATH as an alternative measurement method.
NPATH explained
The essence of NPATH is what the paper calls “acyclic execution path”. This is another fancy technical term that sounds complicated. But it’s quite simple. It just means “unique path through your code”.
This is something that’s pretty easy to visualize with an example. So let’s go back to our earlier example with the insert_default_value function. Here’s the code for it again:
function insert_default_value($mixed)
{
if (empty($mixed)) {
$mixed = 'value';
}
return $mixed;
}
So how many unique paths are there through the insert_default_value function? The answer is two. One unique path is when mixed is empty, and the other is when it’s not.
But that was just the first iteration of our insert_default_value function. We also updated it to use the is_string function as well as the empty check. Let’s do the same thing for it as well.
function insert_default_value($mixed)
{
if (!is_string($mixed) || empty($mixed)) {
$mixed = 'value';
}
return $mixed;
}
With this change, there are now three unique paths through our insert_default_value function. So adding this condition only added one extra path to it. In case you’re wondering, these three paths are:
- When
mixedisn’t a string. (PHP won’t continue evaluating the conditional when that happens. You can read more about it here.) - When
mixedis a string, but it’s empty. - When
mixedis a string, but it’s not empty.
Adding more complexity
Ok, so this wasn’t too hard to visualize so far! In fact, you might have noticed that the NPATH values that we calculated were the same as the ones that we calculated with cyclomatic complexity. That’s because, when functions are that small, both measurement methods are about the same.
But let’s make things a bit more complex now. Let’s imagine that we have an interface that can convert an object to a string. We’ll call it the ToStringInterface interface.
function insert_default_value($mixed)
{
if ($mixed instanceof ToStringInterface) {
$mixed = $mixed->to_string();
}
if (!is_string($mixed) || empty($mixed)) {
$mixed = 'value';
}
return $mixed;
}
Once more, we updated our insert_default_value function to use this interface. We start by checking if mixed implements it using the instanceof operator. If it does, we call the to_string method and assign the value it returns to mixed. The rest of the insert_default_value function is the same.
So what about now? Can you see how many unique paths there are through the insert_default_value function? The answer is six. Yes, we doubled the number of paths through our code. (Yikes!)
Statements are multiplicative
That’s because, with NPATH, adding a new statement like this is multiplicative. That means that to get the total number of paths, we have to multiply the number of paths through the two if conditions together. We already know how many paths there are through each if condition because of our earlier examples.
The first if condition has two possible paths. It’s whether mixed implements the ToStringInterface interface or not. And we saw before that the second if condition has three possible paths. So the total number of paths is 2 * 3 = 6.
This is also where NPATH and cyclomatic complexity diverge. This code only increased the cyclomatic complexity of our function by one. But having a cyclomatic complexity of four is still excellent. However, with NPATH, we can already see how much impact adding one more if conditions can have.
Large functions or methods are dangerous
The point of this example was to show that having a lot of conditionals in your function or method is dangerous. If we added a third conditional to our earlier example, you’d at least double your number of unique paths again. That means, that we’d have at least twelve unique paths through our code.
But how often do we code we just three conditionals? Not that often! Most of the time, we can write functions or methods with a dozen or more conditionals in them. If you had a dozen conditionals in your code, it would have 4096 (2¹²) unique paths! (gasp)
Now, a function or method with twelve unique paths is starting to get complicated. You can still visualize those twelve unique paths. It might just require that you stare at the code for a little while longer than usual.
That said, with 4096 unique paths, that’s impossible. (Well, that’s unless you have some sort of superhuman ability! But, for us, mortals it’s impossible.) Your code is now something beyond complicated. And it didn’t take many statements to get there.
How many unique paths should your code have?
This brings us to the obvious question, “How many unique paths is too many?” We know that 4096 is too many. But twelve is still quite reasonable if a bit on the complicated side.
Code analysis tools tend to warn you at 200 unique paths. That’s still quite a lot. Most of us can’t visualize that many unique paths.
But, again, that’s subjective. It depends on the code or the person reading. That said, it’s a safe bet to say that about 50 is a much more reasonable number of unique paths to have.
Managing complexity in our code
So how do we get from a function or method that has 4096 unique paths to one that has around 50? The answer most of the time is to break your large function or method into smaller ones. For example, let’s take our function or method with 4096 unique paths.
Now, let’s imagine that we broke that function or method in two. If we did that, it would have only six conditionals. (Six! Ha! Ha! Ha!) How many unique paths would there be through that our function or method now?
Well, we’d now only have 64 (2⁶) different unique paths in our function or method. That’s a drastic reduction in complexity! And that’s why breaking up a function or method is often the only thing that you need to do to reduce its complexity.
How to break up functions or methods into smaller ones
In practice, it’s pretty rare that we can just split a function or method in two right down the middle. What will happen most of the time is that you’ll only have small blocks of code that you can extract. So one function or method might become 3-4 functions or methods. The question then becomes what code is good to extract into a separate method or function.
Code that belongs together
The easiest code to spot is code that logically belongs together. For example, let’s imagine that you have a function or method where some of the code validates a date string. It could look something like this:
function create_reminder($name, $date = '')
{
// ...
$date_format = 'Y-m-d H:i:s';
$formatted_date = DateTime::createFromFormat($date_format, $date);
if (!empty($date) && (!$formatted_date || $formatted_date->format($date_format) != $date)) {
throw new InvalidArgumentException();
}
// ...
}
The create_reminder function has an optional date parameter. If we have a date, we want to ensure that it follows the Y-m-d H:i:s format. (You can find details on date formats here.) Otherwise, we throw an InvalidArgumentException.
We do this by creating a DateTime object using the createFromFormat static method. It’s a static factory method that creates a DateTime object by parsing a time using a specific format string. If it can’t create a DateTime object using the given format string and time, it returns false.
The conditional first checks if date is empty or not. Only if it’s not empty do we use the DateTime object that we created. We first check if it’s false and then we compare if our formattedDate matches our date.
We do that by using the format method. It converts our DateTime object to a string matching the given format. If the string returned by the format method matches our date string, we know it was correctly formatted.
Extracting the code
While we can’t see the rest of the create_reminder function, it’s not relevant here. We can see from what we have that this code is there to validate the date argument. And this is what we want to extract into its function.
function create_reminder($name, $date = '')
{
// ...
if (!empty($date) && !is_reminder_date_valid($date)) {
throw new InvalidArgumentException();
}
// ...
}
function is_reminder_date_valid($date)
{
$date_format = 'Y-m-d H:i:s';
$formatted_date = \DateTime::createFromFormat($date_format, $date);
return $formatted_date && $formatted_date->format($date_format) === $date;
}
As you can see above, we moved everything related to the validation of the date to the is_reminder_date_valid function. This function creates ourformattedDate DateTime object using the dateFormat variable. We then do the check to see if formattedDate is false and if the output from the format method is identical to the given date.
In practice, this only removed one check from our conditional. This means that the cyclomatic complexity value of our create_reminder function would also go down by one. You could also have moved the empty check into the is_reminder_date_valid function and then it would have reduced it by two.
But let’s keep the code that we have already. Now, reducing the complexity of method by one might seem insignificant. That said, it can have quite an impact due to the multiplicative nature of NPATH.
Let’s imagine that our create_reminder function had two other if statements with a single condition in them. This would mean that our create_reminder function had 2 * 2 * 4 = 16 unique paths. (This is similar to our earlier example.) With our new if statement using the is_reminder_date_valid function, we’d have 2 * 2 * 3 = 12 unique paths.
That’s a reduction of 25% in the total number of unique paths in your code. So it’s not that insignificant in practice. That’s why you should never think that extracting code for even one conditional statement is a waste of time. It’s always worth it.
Large conditional statements
As we saw in the previous example, removing even one condition in an if statement can have a significant impact. The natural progression of this is to move entire conditional blocks into their functions or methods. This makes a lot of sense if the entire condition block is just to validate one thing.
function send_response(array $response)
{
if (empty($response['headers']) || !is_array($response['headers']) || empty($response['headers']['status'])) {
throw new \InvalidArgumentException();
}
// ...
}
Here’s an example using a fictional send_response function. The function starts with a large if statement containing three conditionals. They’re there to ensure that the response array contains a status header inside the headers subarray.
This type of conditional pattern is widespread with multi-dimensional arrays like this one. But it’s also something that you’ll use a lot when you use instanceof to check the type of a variable. In all those cases, you have to validate the type and structure of the variable before interacting with it.
function send_response(array $response)
{
if (!response_has_status_header($response)) {
throw new \InvalidArgumentException();
}
// ...
}
function response_has_status_header(array $response)
{
return !empty($response['headers']) && is_array($response['headers']) && !empty($response['headers']['status']);
}
So to reduce the complexity of the send_response function, we created the response_has_status_header function. The response_has_status_header function contains the logical inverse of our previous condition. That’s because we want the function to return true if there’s a status header. The previous condition returned true if there wasn’t one.
Aren’t we just hiding the problem?
So this is a question you might have after seen how we break up large functions or methods into smaller ones. After all, the only thing that we’ve done is move code from one function or method to another. How can doing that reduce the complexity of your code?
That’s because what we’ve seen is how to evaluate complexity within the scope of a function or method. We’re not trying to evaluate the complexity of the software as a whole. That said, there’s a correlation between the two. (That’s why a lot of tools only analyze function or method complexity.)
So yes, simply moving code to a separate function or method can have a positive effect. You’re not hiding the problem by doing that. But this only applies to code that’s complex, not code that’s complicated.
If your code was complicated, moving some of it to another function or method won’t make it less so. (Well, that’s unless what made it complicated was the size of the function or method!) Instead, you’d have to focus on fixing the things that made your code hard to understand in the first place. (That’s a topic for another article!)
Combining conditionals together
While breaking functions or methods into smaller ones does fix most issues with complexity, it’s not the only solution either. There’s one other way to reduce complexity that’s worth talking about. That’s combining conditionals together.
function insert_default_value($mixed)
{
if ($mixed instanceof ToStringInterface) {
$mixed = $mixed->to_string();
}
if (!is_string($mixed) || empty($mixed)) {
$mixed = 'value';
}
return $mixed;
}
Here’s our insert_default_value function that we were working with earlier. As we saw, this function had an NPATH value of six. Now, let’s imagine that the to_string method can never return an empty string.
This means that we don’t need to have two separate if statements. Of course, we could keep them as is anyways. But what would happen if we changed our insert_default_value function to this:
function insert_default_value($mixed)
{
if ($mixed instanceof ToStringInterface) {
$mixed = $mixed->to_string();
} elseif (!is_string($mixed) || empty($mixed)) {
$mixed = 'value';
}
return $mixed;
}
If we combined our two if statements using an elseif statement, the NPATH value of the function goes from six to four. That’s a 33% drop in the number of paths in our code. That’s quite significant!
This happened because we added one more path to our three paths from earlier. And then we removed the two paths if statement that we had initially. So our NPATH calculation went from 2 * 3 = 6 to just 4.
Tools
While showing you how to calculate cyclomatic complexity and NPATH values is nice, it’s not that practical. Most of us aren’t going to go back through your code and do this for every function and method that we have already. You need tools to scan all your code and find the functions and methods with high complexity values for you.
Command-line tools
The first set of tools that we’ll look at are command-line tools. These tools are a good starting point since they’re free and you can use them on your development machine. PHP has two popular command-line tools that can analyze the complexity of your code: PHP code sniffer and PHP mess dectector.
PHP code sniffer is a tool for enforcing specific coding standards throughout out your code. Its main purpose isn’t to manage the complexity of your code. That said, it does allow you to enforce that your functions or methods be below a specific cyclomatic complexity value. Unfortunately, it doesn’t support NPATH as a complexity measuring method.
Unlike PHP code sniffer, PHP mess detector is a tool that whose purpose is to help you detect problems with your code. It offers support for both cyclomatic complexity and NPATH measurement methods. It also has a lot of rules to help make your code less complicated on top of less complex.
In practice, you should consider using both tools in your projects. But that might be a bit overwhelming if you haven’t used either tool before. So, if you had to pick one, it would be PHP mess detector. It’s the better choice for the task of evaluating the complexity of your code.
Code quality services
If you work in a team, using a command line tool might not be enough for you. You might want a more automated way to check and enforce low complexity in everyone’s code. In that scenario, you might want to use a code quality service instead of a command-line tool.
Code quality services work by connecting to your git repository. Using that connection, they analyze your code each time that there’s a commit or a new pull request. If there’s an issue, they alert you via your chosen communication method. They also support status messages for GitHub and other git repository hosting services.
In terms of choice, PHP has a bit more of a limited selection of code quality services. The big three to choose from are Codacity,
Code Climate and Scrutinizer. All three are pretty much the same in terms of features.
The big difference between them is the price. They all offer free integrations for open source projects. But both Codacity and Code Climate charge per user per month which can make them quite pricey. Scrutinizer only charges a flat price per month.
Complexity isn’t that complex
So this took us a little while, but we’ve made it through! Complexity is a topic that can be quite intimidating to developers. But that’s because of the theory and the language surrounding the concept. They make it seem more complicated than it is in practice.
The truth is that managing software complexity is almost only about the size of your functions and methods. The mathematics behind it is just there as a way to quantify the effect of the size of your function or method. But it’s not necessary for you to be able to do that to reduce complexity in your code.
Just focus on keeping your functions and methods small. If you see that they’re getting large, find a way to break them into smaller ones. That’s all that there is to it.